Blockchain Research Newsletter #7: Coded Merkle Tree: Solving Data Availability Attacks in Blockchains
Blockchain Research Newsletter #7: Coded Merkle Tree: Solving Data Availability Attacks in Blockchains
By Mikerah and John Adler
In this edition of the Blockchain Research Newsletter, we are covering a protocol for solving data availability attacks in blockchains called SPAR (Sparse Fraud Protection) which leverages a new accumulator called a Coded Merkle Tree. This paper was recently published by Yu et al., and provides an efficient data availability scheme for light clients. The authors have implemented a version of SPAR for a Bitcoin client, highlighting the practical relevance of their work.
Motivation
Light clients need to download block headers from a trusted set of full nodes and verify these headers in order to ensure that they represent the blockchain. However, in practice, this is hard to guarantee. Recent work has shown that with fraud proofs, light clients can reduce the trust requirements on the set of full nodes they need to connect to. In fact, with fraud proofs, the trust assumption reduces to only needing a single, honest full node instead of a trustworthy set of full nodes. However, it is possible for a malicious full node to withhold parts of a block in order to fool a light client in to accepting a block header associated with that block. This is known as the data availability problem. Restated, how can a light node ensure that a block whose integrity it is trying to ascertain is available to others in the network?
Background
Before diving into the particulars of how SPAR attempts to solve the data availability problem, one needs a high-level understanding of erasure coding, a technique used to encode data into pieces for efficient retrieval and reconstruction at a later time.
Erasure Coding
Erasure coding is an information theoretic way to extend n-byte sized data into m-byte sized data such that m > n and one need only n of the m pieces in order to reconstruct the data. The code rate is n/m and n’/n is the reception efficiency, where n’ denotes the number of symbols needed to retrieve the data. The code rate tells us the proportion of the data that is non-redundant i.e. the minimum amount of information needed to reconstruct the original data. Erasure coding has applications in distributed systems, most notably in RAID systems. One of the first proposals for using erasure coding to combat data availability was by Buterin. That work was formalized and expanded upon by Al-Bassam in 2018.
Description of SPAR
Before going into the SPAR scheme, we will cover some assumptions it makes about light nodes and full nodes and present the coded merkle tree construction.
Security and Network Model
Light nodes are connected to a set of full nodes in which at least one of the full nodes is honest. The light nodes are not necessarily connected to one another. There is at least one full node connected to all light nodes. All full and light nodes get sent messages about block data. The network is synchronous and network communication is lossless and secure. Users can send messages anonymously. Finally, the scheme allows for a dishonest majority of full nodes (or, more precisely, a dishonest majority of block producers).
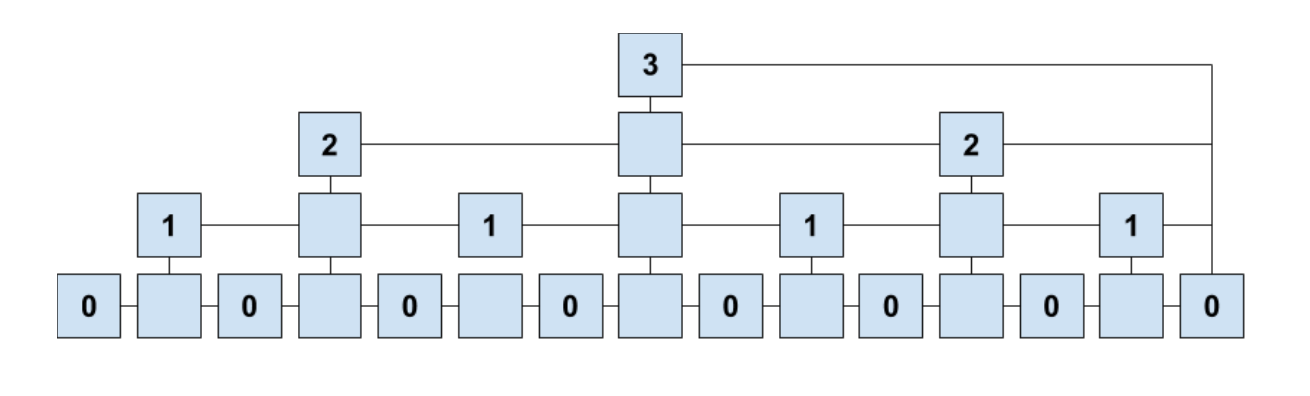
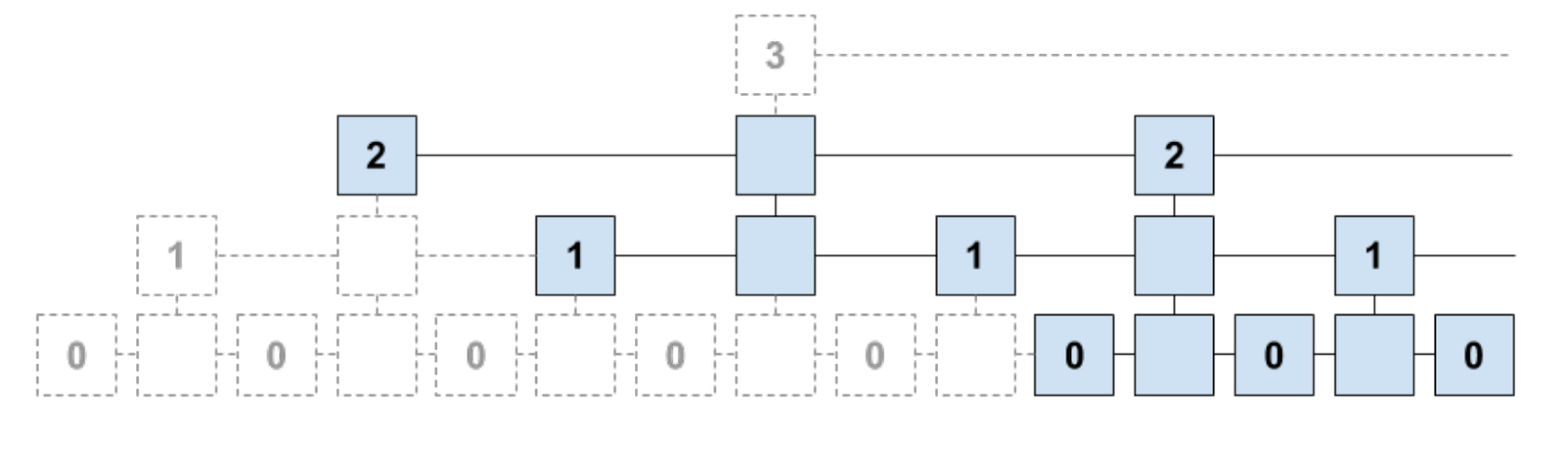
Coded Merkle Trees
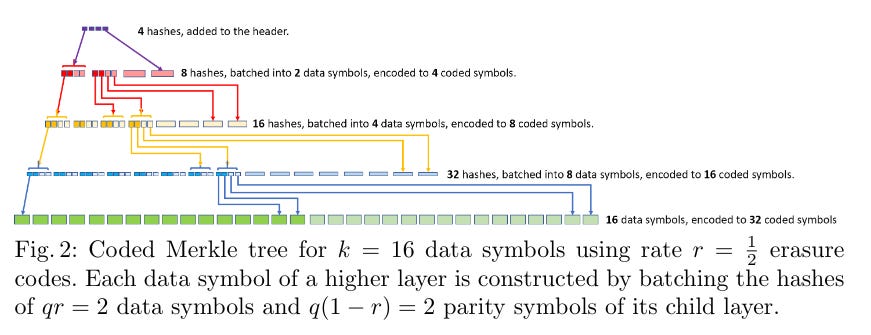
A coded merkle tree (CMT) is a modified merkle tree in which every layer of the merkle tree is erasure coded. A CMT is constructed as follows: Given k data symbols which are formed from the block, a rate r such that r is at most 1, an undecodable ratio of A,
The leaves of the CMT is formed by first ordering the k data symbols and then placing the the next n-k encoded data symbols. Here, n = k/r. Take the hash of all these symbols.
Then, batch q of these coded symbols to form 1 data symbol for the next layer. Now, we have n/q data symbols.
Iterate this process until you get only t hashes such that t is at least 1.
In the example picture above, k = 16, r = 0.5, q = 4 and t = 4. A vanilla merkle tree is a CMT where r = 1 and q = 2.
The benefits of CMTs are two-fold. First, light clients only need to randomly sample relevant layers in order to prove the availability of every layer. Second, for full nodes, they can prove that layers have been incorrectly encoded and reject the block associated with the CMT and send a proof showing this.
SPAR Scheme
We are now ready to give an overview of the SPAR scheme.
First, a block producer will create a block, along with a CMT root. They will then propagate this to all other nodes in the network. The other full nodes are expected to verify the availability of the block and the correctness of the CMT root. The light clients only need the CMT root in order to ascertain the availability of a given block.
In order for a light client to be reasonably convinced of the availability of a given block, they will request random samples from several full nodes that they are connected to. In particular, they will sample for layers of a given block’s CMT. If the light client receives all the samples it requested within a fixed time, then they can accept that block as available. If the client doesn’t receive all the samples it requested within the timeframe, then it marks that block as pending and will redo the procedure at a later time. On the other hand, if they receive a bad proof i.e. an incorrectly coded proof, they reject that block and update the corresponding layer of the CMT for that block.
For other full nodes in the network, they are in charge of responding to light client queries and ascertaining the availability of blocks. When they receive samples from light clients, they download the original block from other full nodes and attempt to decode the associated CMT. If the CMT was incorrectly coded then they will propagate a proof that the given block is unavailable to all the other nodes, both light and full, in the network. If they have successfully decoded a block, then they will declare this to all the other nodes.
Conclusion
We covered a novel scheme called SPAR that aims to solve the data availability problem for light clients. It makes use of a novel hash-based accumulator called coded merkle tree in order to guarantee its efficiencies. If you would like to read the paper in depth, you can do so here.